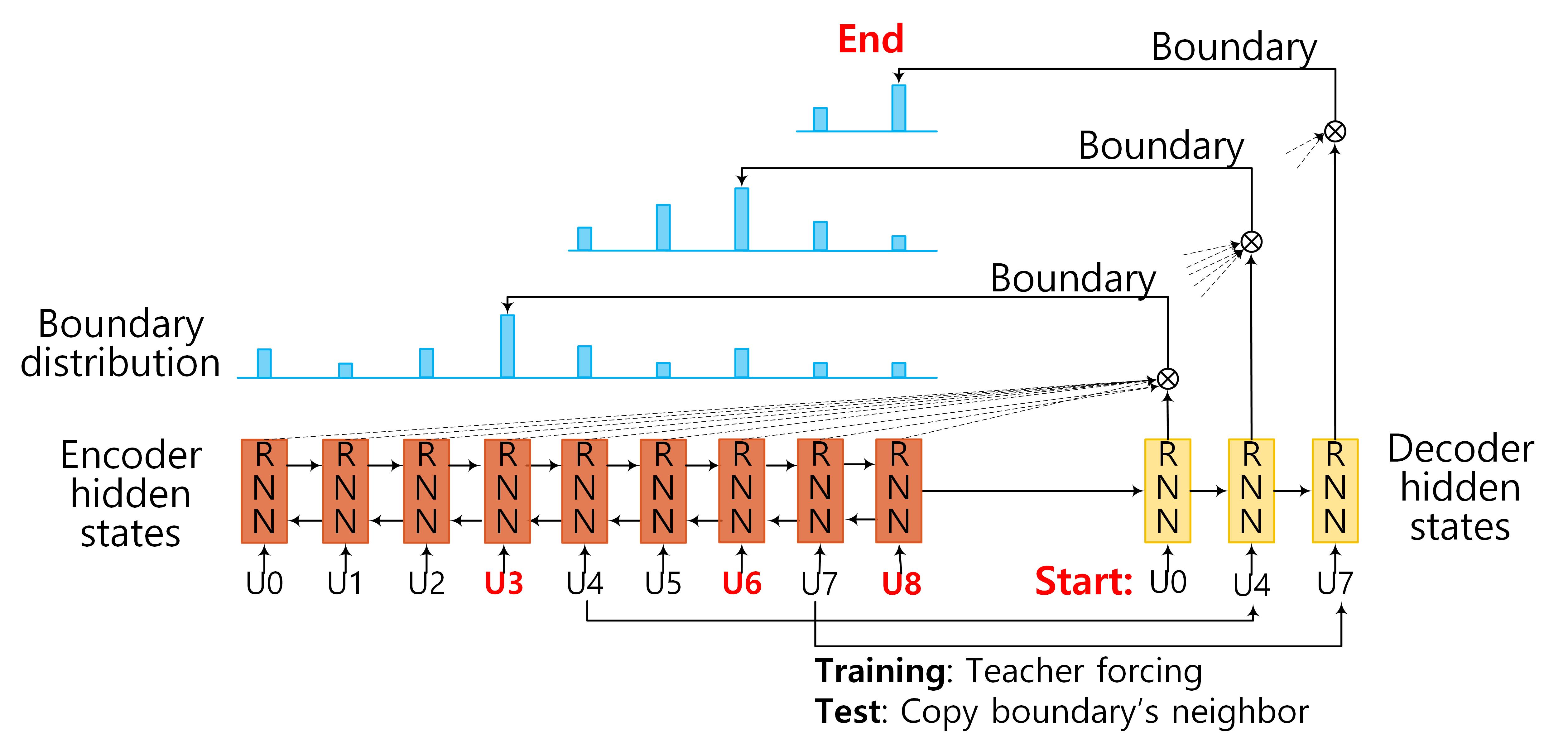
Figure 1: Model Architecture of SEGBOT. Input sequence: U1,U2,...,U8. Identified boundaries: U3, U6, and U8.
1. Encoding Phase:
We encode the input sequence \(\boldsymbol{X}=(\boldsymbol{x}_1,\boldsymbol{x}_2, \ldots, \boldsymbol{x}_N)\) using a RNN. RNNs capture sequential dependencies, and with hidden cells like long short-term memory (LSTM) and gated recurrent unit (GRU), it can capture long distance dependencies without running into the problems of gradient vanishing or explosion. In our model, we use GRU to encode input sequences, which is similar to LSTM but is computationally cheaper. The GRU activations at time step `n` are computed as follows: \[ \boldsymbol{z}_n = \sigma (\boldsymbol{W}_z \boldsymbol{x}_n + \boldsymbol{R}_z \boldsymbol{h}_{n-1} + \boldsymbol{b}_z) \tag{1} \] \[ \boldsymbol{r}_n= \sigma (\boldsymbol{W}_r \boldsymbol{x}_n + \boldsymbol{R}_r \boldsymbol{h}_{n-1} + \boldsymbol{b}_r) \tag{2} \] \[ \boldsymbol{n}_n = \tanh (\boldsymbol{W}_h \boldsymbol{x}_n + \boldsymbol{R}_h (\boldsymbol{r}_n \odot\boldsymbol{h}_{n-1}) + \boldsymbol{b}_h) \tag{3} \] \[ \boldsymbol{h}_n = \boldsymbol{z}_n \odot \boldsymbol{h}_{n-1} + (1-\boldsymbol{z}_n) \odot \boldsymbol{y}_n \tag{4} \] where \(\sigma()\) is the sigmoid function, \(\tanh()\) is the hyperbolic tangent function, \(\odot\) is the element-wise multiplication, \(\boldsymbol{z}_n\) is update gate vector, \(\boldsymbol{r}_n\) is reset gate vector, \(\boldsymbol{n}_n \) is the new gate vector, and \(\boldsymbol{h}_n\) is the hidden state at time step `n`. \(\boldsymbol{W}\), \(\boldsymbol{R}\), \(\boldsymbol{b}\) are the parameters of the encoder that we need to learn. We use a bi-directional GRU (BiGRU) network to memorize past and future information in the input sequence. Specifically, each hidden state of BiGRU is formalized as: \[ \boldsymbol{h}_n =\overrightarrow {\boldsymbol{h}}_n \oplus \overleftarrow {\boldsymbol{h}}_n \] where \(\oplus\) indicates concatenation operation, \(\overrightarrow {\boldsymbol{h}}_n\) and \(\overleftarrow {\boldsymbol{h}}_n\) are hidden states of forward (left-to-right) and backward (right-to-left) GRUs, respectively. Assuming the size of the GRU layer is `H`, the encoder yields hidden states in \(\boldsymbol{h} \in \mathbb{R}^{N \times 2H}\).2. Decoding Phase:
Since the number of boundaries in the output vary with the input, it is natural to use RNN-based models to decode the output. At each step, the decoder takes a start unit (i.e., start of a segment) `U_m` in the input sequence as input and transforms it to its distributed representation \(\boldsymbol{x}_m\) by looking up the corresponding embedding matrix. It then passes \(\boldsymbol{x}_m\) through a GRU-based (unidirectional) hidden layer. Formally, the decoder hidden state at time step `m` is computed by: \[ \boldsymbol{d}_m = GRU(\boldsymbol{x}_m,\boldsymbol{\theta}) \] where \(\boldsymbol{\theta}\) are the parameters in the hidden layer of the decoder, which has the same form as described by Equations (1) -- (4). If the input sequence contains `M` boundaries, the decoder produces hidden states in \(\boldsymbol{d} \in \mathbb{R}^{M \times H}\) with `H` being the dimensions of the hidden layer.3. Pointing Phase:
At each step, the output layer of our decoder computes a distribution over the possible positions in the input sequence for a possible segment boundary. For example, considering Figure 1, as the decoder starts with input `U0`, it computes an output distribution over all positions (`U0` to `U8`) in the input sequence. Then, for `U4` as input, it computes an output distribution over positions `U4` to `U8`, and finally for `U7` as input, it computes a distribution over `U7` to `U8`. Note that unlike traditional seq2seq models (e.g., the ones used in neural machine translation), where the output vocabulary is fixed, in our case the number of possible positions in the input sequence changes at each decoding step. To deal with this, we use a pointing mechanism in our decoder.Recall that \(\boldsymbol{h} \in \mathbb{R}^{N \times 2H}\) and \(\boldsymbol{d} \in \mathbb{R}^{M \times H}\) are the hidden states in the encoder and the decoder, respectively. We use an attention mechanism to compute the distribution over the possible positions in the input sequence at decoding step `m`: \[ u^m_j = \boldsymbol{v}^T \tanh (\boldsymbol{W}_1 \boldsymbol{h}_j +\boldsymbol{W}_2 \boldsymbol{d}_m), ~~for~ j \in (m, \ldots, M) \] \[ p(y_m|\boldsymbol{x}_m) = \textrm{softmax}(\boldsymbol{u}^m) \] where `j \in [m,M]` indicates a possible position in the input sequence, and softmax normalizes `u_j^m` indicating the probability that the unit `U_j` is a boundary given the start unit `U_m`.